Il y a peu de temps, je me suis lancé dans la fabrication de magi-gemmes et j’ai créé La Magi-Gemme Factory. Et quelle aventure ! C’est éminent compliqué à réaliser (mais secret industriel, je ne peux vous en dire plus). Au lieu de cela je vais revenir sur une expérience vécue lors de la création de ce business et d’une solution que j’ai mise en œuvre pour m’aider à produire toujours plus …
Les Magi-Gemmes sont des pierres précieuses magiques créées à l’aide d’une technologie avancée. Elles ont la capacité de modifier leur forme et leurs couleurs selon les souhaits de celui qui les possède. Chaque gemme est unique et peut être façonnée pour répondre aux besoins spécifiques du propriétaire.
Le processus de fabrication des Magi-Gemmes commence par la collecte des matières premières nécessaires, telles que du quartz, du corail, de l’améthyste ou encore du jade. Ces matières premières sont ensuite broyés en poudre fine puis moulés dans un moule en forme de gemme. Une fois cette étape terminée, les gemmes sont placées dans une chambre spécialement conçue pour activer leurs propriétés magiques. Cette chambre est remplie d’un gaz magique composant plusieurs éléments alchimiques rares qui donneront aux gemmes leur caractère unique et leur capacité à changer de forme et/ou couleur selon la volonté du propriétaire. Enfin, chaque gemme est polie avec soin afin qu’elle brille comme un vrai joyau !
Quel est le problème ?
Comme tout bon industriel, la fabrication ne peut se faire que grâce à des machines très complexes, et ces machines ont parfois quelques pannes. Heureusement, les Technomages sont présents pour remettre en fonction ces machines et me garantir une productivité optimale. Et pour continuer de toujours mieux produire mes Technomages renseignent à chaque panne, les causes des problèmes rencontrés et les actions qui leur ont permise réparer cette situation.
Pour être encore meilleurs, je souhaitais que mes techniciens puissent eux aussi avoir un peu de magie : un assistant qui les aide à trouver dans la base de connaissance les causes de pannes rencontrées et surtout donner les actions à réaliser pour corriger le plus rapidement possible.
Voici un extrait CSV de cette base données :
Scie circulaire ;Pann: Vib. excs, Cs: lame émoussée, Action: Remplacer la lame
Fraiseuse;Intervn sur panne ralentissement mach. Constaté fuite huile, remplacé joint et vérifié niveau d'huile. Réglages effectués, problème résolu.
Chambre à gaz;Intervn Chbr à gaz: bruit anorml, constat fissures/déformations parois int. Résolu en remplaçant les pièces défectueuses et vérifiant le bon fonctionnement de la machine.
Scie circulaire ;Pann: MvQtC; Cs: RoultUsd; Actn: RmvdRlt, InstldNwRlt.
Chambre à gaz;Pnne : Basculement inapprop. des vlvs & vanes, code d'erreur "". Action : Vérif et ajustmt vlvs/vanes + redémarrage mach.
Comme nous le constatons, mes techniciens n’ont pas été très rigoureux dans leurs saisies, et prennent quelques libertés (fautes d’orthographe, fautes de grammaires, abréviations, …) ce qui rend la construction d’une base de données difficile.
Himelutu q’est-ce qu’il karudon
Traduction : « mais qu’est-ce qu’il raconte ? » en Magirien, langue officielle de ce pays magnifique.
Revenons un peu à la réalité, vous avez déjà vu des applications de ce type, des applications où il est nécessaire de comprendre de manière fine le contenu d’un texte de manière programmatique pour en réaliser des actions ? Il y en a en effet une pléthore. C’est tout simplement ce que j’expliquait dans mon précédent article, le domaine de la Sémantique t du NLP (https://kbeaugrand.blog/2023/06/11/a-vos-prompts-avec-azure-open-ai/).
Et si dans mon monde imaginaire, je n’ai pas réussi à trouver une solution, c’est peut-être tout simplement qu’elle n’est pas magique…
Aujourd’hui, je vais aller un peu plus dans le détails de l’utilisation de Azure Open AI en mettant en œuvre le Semantic Kernel et une base de données Sémantique et créer une application de gestion réalisant une recherche dans cette base connaissance.
Semantic Kernel ?
Le SemanticKernel (ou SK pour les intimes) est un Framework de développement édité par Microsoft, en OpenSource permettant de faciliter les interactions avec les modèles IA de type Open AI afin de résoudre des problématiques en utilisant ces modèles et la sémantique pour exprimer ses attentes.
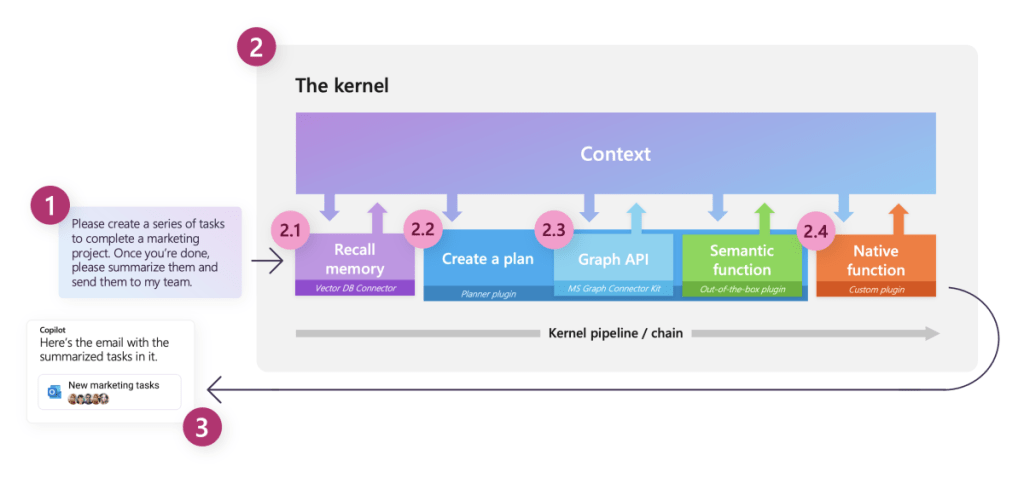
Il fournit des APIs et un orchestrateur permettant :
- la prise en compte de l’intention (Ask),
- La demande est la première pièce importante dans le traitement d’une action. Cette demande peut être effectuée par l’utilisateur lui-même (et là, nous faisons appel au NLP pour la compréhension), mais également par le développeur de manière programmatique.
- la recherche d’informations utiles (Memories),
- C’est un moment important dans le traitement d’une demande, il faut parfois se remémorer des informations pour pouvoir répondre à des questions. Nous allons alors pouvoir utiliser des bases de données contenant nos informations pour faire appel à ces informations et exécuter l’action demandée.
- un planificateur des tâches (Planner),
- Parfois les demandes sont complexes et puisqu’elles peuvent venir de l’utilisateur, risquent de changer, nous avons toutes les compétences mais nous ne savons pas réellement comment les mettre en œuvre et les séquencer par exemple. Nous avons alors besoins d’un planificateur qui va comprendre l’intention et planifier l’ordonnancement de chacune de ces tâches.
- des connecteurs (Connectors),
- Certaines tâches (une grande partie en fait), nécessitent des interactions avec des services externes (la météo, l’envoi un email, …), il faudra alors réaliser des connecteurs afin de pouvoir les solliciter en fonction des actions attendues.
- des fonctions personnalisées (Functions),
- Pièce essentielle dans tout traitement d’une action, la fonction permet de réaliser une partie de l’action demander. Nous allons le voir ensemble, nous pouvons développer cette fonction avec du code natif (C# ou Python), mais nous pouvons aussi nous appuyer sur le modèle LLM pour réaliser pour nous des actions complexes sans avoir à se soucier de comment l’implémenter, ce sont les fonctions Sémantiques.
- et enfin une réponse (Response)
- Une fois notre exécution réalisée, et le résultat obtenu, il convient aussi de donner une réponse. La réponse peut être sémantique pour un utilisateur, ou tout simplement des données dans le cadre d’un appel programmatique.
La présentation du Semantic Kernel ressemble de plus en plus à de la présentation d’un noyaux permettant la réalisation d’un « Copilot », et oui on entend le terme partout chez Microsoft (peut-être un peu trop), quoi qu’il en soit, je vais ici faire une utilisation de ce Framework de manière programmatique et dans une simulation d’une application de gestion, pour vous montrer qu’il n’y a pas que les chats dans la vie (il y a aussi les poneys, les licornes, …).
Démarrage d’un projet SK
Pour démarrer sur mon projet avec un Semantic Kernel, je vous propose de réaliser une application .NET MAUI permettant d’exécuter un front sur divers appareils avec un seul langage : le C# !
Je ne vais pas détailler ici toutes les étapes, mais seulement les éléments clefs, vous pouvez cependant suivre ce repository : https://github.com/kbeaugrand/SemanticKernelDemo ou j’ai archivé cette démonstration ainsi qu’un petit supplément (le générateur de cette petite histoire basé lui aussi sur le SK).
Une fois mon projet initialisé, j’ai installé les packages NuGet permettant l’utilisation du framework :
dotnet add package Microsoft.SemanticKernel --version 0.15.230609.2-preview
dotnet add package Microsoft.SemanticKernel.Abstractions --version 0.15.230609.2-preview
dotnet add package Microsoft.SemanticKernel.Core --version 0.15.230609.2-preview
Vous l’avez remarqué, nous sommes actuellement sur une version préliminaire de ce Framework et tous les packages sont actuellement en preview. La communauté est très active, et je vois régulièrement des nouveautés dans le code que je n’avais pas soupçonné, je vous encourage vivement à vous connecter sur leur salon Discord pour constater la dynamique de cette communauté, et également d’y participer, ils sont tous à l’écoute des idées et des contributions en tout genre.
Avec cela je vais également ajouter la librairie Azure.Identity, afin de faciliter l’authentification de mon application sur les services Open AI avec mon identité.
Maintenant, configurons le moteur du SemanticKernel dans notre application. Dans le MauiProgram, rajoutons les lignes suivantes lors de la création de notre application Maui :
_ = builder.Services.AddSingleton((_) =>
{
var azureIdentity = new VisualStudioCredential();
var kernel = Kernel.Builder
.WithAzureTextCompletionService(
deploymentName: "text-davinci-003",
endpoint: "https://weu-jarvis-ai.openai.azure.com/",
credentials: azureIdentity)
.Build();
return kernel;
});
Je n’en ai pas parlé, mais juste avant j’ai créé sur Azure une instance Azure Open AI, ce qui m’a permis de récupérer le Endpoint : « https://weu-jarvis-ai.openai.azure.com/ » de mon instance. Ici j’ai choisi d’utiliser mon identité sur Azure pour m’authentifier sur le service
n.b : en réalité, le programme vas s’authentifier avec votre compte pour récupérer la clé primaire de Azure Open AI pour ensuite l’utiliser lors des échanges avec le service.
Dans mon Azure Open AI Studio, j’ai également déployé un modèle text-davinci-003, ce modèle me permet d’utiliser la complétion (que nous allons voir ensemble) :
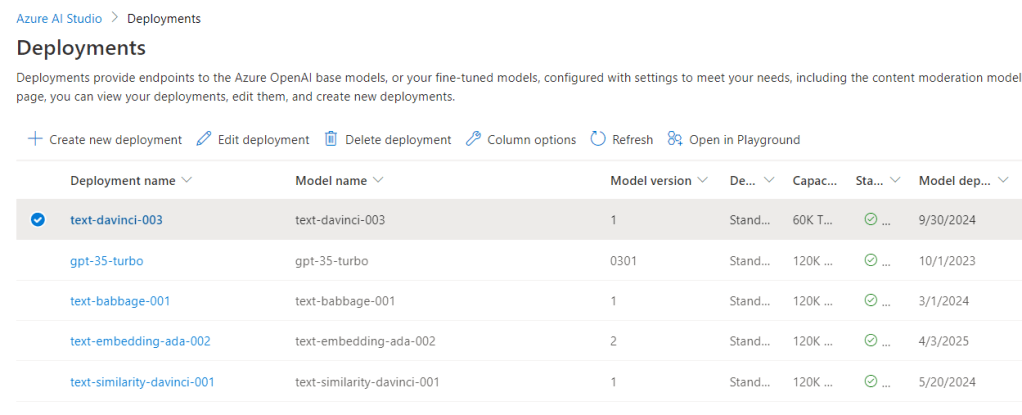
Nous voyons ici que je peux télécharger et utiliser différents modèles en même temps au seins de mon application. Nous sommes donc prêts pour créer notre application.
Fonction Sémantique
La première étape de mon application sera de créer une fonction sémantique qui nettoiera les données de mes techniciens afin de la rendre un peu plus « propre ».
Nous pouvons constater ci-dessous le résultat de cette complétion avec une partie du jeux de données que je vous ai présenté :

Je vous le rappelle, le modèle LLM est créé pour réaliser une complétion en choisissant les caractères et mots les plus probables (même s’ils ne sont pas dans l’énoncé). Pour m’assurer que le modèle n’invente pas des choses qui n’ont pas étés spécifiés, je vais tenter de réduire un maximum les possibilités qu’il soit « inventif » :
- En réduisant la température à 0
- En réduisant le TopP à 0 également
- Dans le prompt, en lui disant : « En utilisant uniquement les informations présentes »
Mon prompt est prêt, je vais pouvoir donc l’ajouter à mon application. Je vais déjà commencer par ajouter un répertoire SKPrompts à mon application. Ensuite l’arborescence devra ressembler à ceci:
Resources
|__Raw
|____SKPrompts
|______SkillName
|________FunctionName
|__________config.json
|__________skprompt.txt
Le skill correspond en fait à un ensemble de fonctions faisant partie d’une compétence particulière accessible dans votre Semantic Kernel. Ici, j’ai nommé cette skill Encoder et ma fonction AnomalyEncode. Le fichier skprompt.txt est quant à lui le fichier texte contenant le prompt qui sera envoyé au modèle LLM, j’ai donc remplis ce fichier avec le contenu suivant :
Les informations ci-dessous représentent les informations concernant un problème rencontré par un équipement de production. L'opérateur de maintenance a saisi dans les commentaires la description du problème ainsi que les informations permettant la remise en fonction.
En utilisant uniquement les informations présentes donner une description détaillée de la panne:
- Symptôme
- Cause
- Actions réalisées
"{{ $INPUT }}".
Remarquez, ici que j’utilise un token de remplacement que SK va remplacer pour nous à partir des données que j’aura dans ma base de données.
Ensuite je vais renseigner le contenu du fichier config.json, ce fichier contient en fait la configuration qui est envoyée à Azure Open AI lors de l’inférence, il s’agit alors des différents paramètres pour l’exécution de la complétion :
{
"schema": 1,
"type": "completion",
"description": "a function that take an input from the operator and encode that to extract the symptom, root cause and action taken to resolve the issue.",
"completion": {
"max_tokens": 1500,
"temperature": 0,
"top_p": 0,
"presence_penalty": 0,
"frequency_penalty": 0
}
}
Dernière étape pour l’ajout de ma fonction sémantique, je m’assure que le contenu de cette skill soit présente dans les Assets de mon package MAUI dans la sortie de mon build en changeant ses propriétés au travers de Visual Studio et je demande à SK de le charger lors de son initialisation :
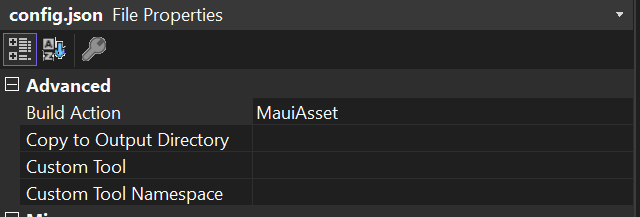
kernel.ImportSemanticSkillFromDirectory(Path.Combine(FileSystem.Current.AppDataDirectory, "SKPrompts"), "Encoder");
J’ai également créé une fonction déclenchée lors du démarrage de mon application MAUI afin de copier les fichiers présents dans mon package vers le répertoire de l’application afin que le chargement s’effectue correctement.
Cette fonction est maintenant prête, je vais la laisser de côté maintenant afin de pouvoir me concentrer sur la partie « Memory », ou comment enregistrer les résultats de la complétion dans une base de données …
Base de données Vectorielle
La base de données vectorielle est une base de données, où l’on va transformer chacun des mots d’une phrase sémantique en « vecteurs », qui permet (en vulgarisant un max) de transformer les mots de votre phrase en tableau numériques (les vecteurs), en vue d’effectuer des calculs de distances entre les mots ayant la sens le plus proche de votre donnée d’entrée. Autrement dit, une fois la donnée enregistrée sous forme de vecteurs, il suffit de chercher dans la base de données les entrées dont la distance est la plus courte pour retrouver des éléments dont la signification est la plus proche.
Dans OpenAI, les éléments textuels transformés ainsi en vecteurs s’appellent des Embeddings.
Dans mon exemple je vais utiliser une base données « Simple » qui n’est pas une base de données qui effectuera la recherche vectorielle, mais uniquement le stockage de ces vecteurs (c’est ensuite le SK qui effectuera les filtres dans l’application au runtime.
Je vais donc maintenant ajouter les packages NuGet qui seront en charge de me donner le support de la base de données SQLite:
dotnet add package Microsoft.SemanticKernel.Connectors.Memory.Sqlite --version 0.15.230609.2-preview
Ensuite, je peux rajouter la configuration à mon SK pour bénéficier du memory storage ainsi que du service de génération des embeddings au travers du modèle text-embedding-ada-002 :
private static async Task<IKernel> CreateKernel()
{
var azureIdentity = new VisualStudioCredential();
var memoryStore = await SqliteMemoryStore.ConnectAsync("memory.db");
var kernel = Kernel.Builder
.WithAzureTextCompletionService(
deploymentName: "text-davinci-003",
endpoint: "https://weu-jarvis-ai.openai.azure.com/",
credentials: azureIdentity)
.WithAzureTextEmbeddingGenerationService(
deploymentName: "text-embedding-ada-002",
endpoint: "https://weu-jarvis-ai.openai.azure.com/",
credential: azureIdentity)
.WithMemoryStorage(memoryStore)
.Build();
kernel.ImportSemanticSkillFromDirectory(Path.Combine(FileSystem.Current.AppDataDirectory, "SKPrompts"), "Encoder");
return kernel;
}
Effectuons le ré-encodage
Venons-on au cas pratique, comment assembler ces différentes briques afin de réencoder notre base de données et disposer ensuite d’un historique « propre » des incidents et solutions apportées.
J’ajoute maintenant un job lors du démarrage de mon application afin de lire le fichier CSV que je vous avais présenté en tout début :
var dataFilePath = Path.GetFullPath(
Path.Combine(Directory.GetCurrentDirectory(), "C:\\Users\\KevinBEAUGRAND\\source\\repos\\kbeaugrand\\MagiGemm-SemanticKernel\\ScenarioAuthor\\bin\\Debug\\net7.0\\Magi-Gemmes_shufled.csv"));
if (!File.Exists(dataFilePath))
{
return;
}
var lines = await File.ReadAllLinesAsync(dataFilePath);
var lineNumber = 0;
var kernel = await CreateKernel();
var encodingFunc = kernel.Func(skillName: "Encoder", functionName: "AnomalyEncode");
foreach (var line in lines)
{
string userPrompt = null;
try
{
userPrompt = line.Split(";", StringSplitOptions.TrimEntries)[1];
}
catch (Exception)
{
Debug.WriteLine($"Failed to parse line {lineNumber}");
continue;
}
lineNumber++;
var ctx = kernel.CreateNewContext();
if ((await ctx.Memory.GetAsync(collection: "maintenance", key: lineNumber.ToString())) != null)
{
continue;
}
ctx["INPUT"] = userPrompt;
var encoding = await encodingFunc.InvokeAsync(ctx);
if (encoding.ErrorOccurred)
{
continue;
}
Debug.WriteLine($"Saving line {lineNumber}...");
await ctx.Memory.SaveInformationAsync(
collection: "maintenance",
text: encoding.Result,
id: lineNumber.ToString());
}
Debug.WriteLine("All entries encoded");
Comme nous pouvons le voir ici, le code est simple:
- je lis le fichier texte,
- pour chacune des lignes :
- je crée un nouveau context SK,
- j’ajoute au contexte l’input de l’utilisateur
- j’appelle la fonction sémantique d’encodage
- j’utilise le contexte pour sauvegarder en mémoire le résultat de l’encodage
Ci-dessous un exemple ce que que le moteur LLM réalise alors pour moi :
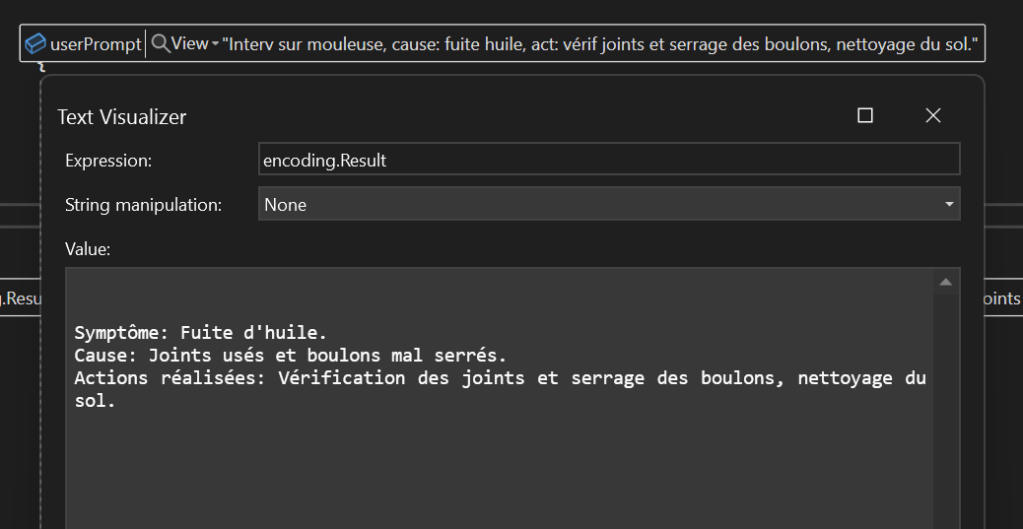
Je vais maintenant le laisser travailler tranquillement le temps qu’il effectue cela sur toute la base de données.
Il faut retenir qu’à chaque encodage il faut appeler le modèle LLM, cette opération prend quelques secondes, donc sur ma base de données de plus de 5000 entrées, cela prend quelques heures.
Some time later…
Vient maintenant le temps de donner à mon application la capacité de trouver dans ma base de données des incidents proches de celui que mon Technomage cherche à résoudre.
Je vais donc créer une skill capable de prendre en input la question de l’opérateur, rechercher les éléments rapprochant dans la base de données et de donner les actions à réaliser pour corriger la panne :
{{ textmemory.recall $INPUT }}
L'historique ci-dessus contient un ensemble de pannes ayant apparu et étant maintenant résolus.
Un opérateur recherche maintenant une solution pour une panne similaire.
Problème en cours: {{ $INPUT }}.
Vous êtes un assistant virtuel à qui l'opérateur demande des informations. Aidez-le à trouver ce qu'il faut faire. Donner une cause la plus probable en fonction de cet historique et proposer les actions qu'il doit réaliser pour résoudre la situation sous la forme de bullet-points.
Un petit arrêt sur image
Ici, vous découvrez une nouvelle fonctionnalité, je fais en effet appel ici à la fonction textmemory.recall en lui fournissant l’input de l’utilisateur. Pour bénéficier de cette fonctionnalité, il suffira de rajouter lors de l’initialisation de votre kernel l’enregistrement de cette compétence :
kernel.ImportSkill(new TextMemorySkill(), "TextMemory");
Reste maintenant à réaliser la fonction qui fera appel à notre kernel pour donner la réponse à l’utilisateur :
private async Task FindSolution()
{
var context = _kernel.CreateNewContext();
context["INPUT"] = _userPrompt;
context[TextMemorySkill.CollectionParam] = "maintenance";
context[TextMemorySkill.LimitParam] = "10";
var solution = await _kernel.Func("Resolver", "HelpMe")
.InvokeAsync(context);
_result = solution.Result;
}
Si l’on détail un peu ce code, on remarquera que je fourni au contexte SK les paramètres permettant de récupérer les informations nécessaires à la recherche dans la mémoire (nom de la collection, nombre max d’items retournés).
En regardant un peu dans les entrailles de SK, je peux voir qu’il a effectivement recherché les éléments les plus proches et envoi au modèle LLM le prompt suivant :
Symptôme : La mouleuse ne fonctionne pas.
Cause : Il y a une fuite d'huile du moteur.
Actions réalisées : Remplacer le joint pour réparer la fuite d'huile et rétablir le fonctionnement de la mouleuse.
Symptôme : La mouleuse présente une baisse de pression du liquide, une mauvaise performance et une consommation d'énergie anormale, ainsi qu'une fuite de composants électriques.
Cause : La cause de la panne est probablement due à des problèmes avec les joints toriques et les pièces mobiles.
Actions réalisées : L'opérateur de maintenance a procédé à une inspection des joints toriques et des pièces mobiles afin de déterminer la cause de la panne et de remettre l'équipement en fonction.
...
Symptôme: L'écoulement est irrégulier.
Cause: Il y a une fuite d'huile.
Actions réalisées: Le joint a été remplacé et l'étanchéité a été vérifiée."]
L'historique ci-dessus contient un ensemble de pannes ayant apparu et étant maintenant résolus.
Un opérateur recherche maintenant une solution pour une panne similaire.
Problème en cours: Fuite mouleuse.
Aidez-le à trouver ce qu'il faut faire.
Ca me semble pas mal du tout ça ! Allez regardons ce que cela donne dans MAUI :

Excellent !
Conclusions
Depuis la sortie de ces modèles via Chat GPT, il y a eu beaucoup de bruit autour de Azure Open AI, mais j’avoue que cela me semble un peu déconnecté de la réalité. Il est cependant vrai que cette technologie offre de nouvelles perspectives en matière de traitement de la sémantique.
J’apprécie particulièrement la capacité que nous avons maintenant de faire bénéficier à moindre coût dans nos applications de ces modèles et plus généralement de la NLP intégrée.
Dans mon précédent billet, je disais que GPT n’était pas une encyclopédie, je maintiens ce que je dit et nous pouvons voir comment nous pouvons « brancher » un ensemble de compétences à ces modèles LLM pour leur permettre d’être cette fois-ci « intelligent ».
Il y’a en effet une fonctionnalité du Semantic Kernel que j’ai pu expérimenté, mais qui selon moi était encore balbutiante : Le planner. Ceci permet au semantic kernel de découvrir l’ensemble des skills enregistrées et en fonction d’une question posée, de pouvoir exécuter les actions nécessaires afin de résoudre le problème. Il s’appui sur les capacités cognitives de LLM ainsi que sur les déclarations des fonctions que nous créons pour réaliser un plan d’exécution et exécuter l’enchainement. Mais lors de mes tests le résultat n’était pas aussi concluant que je l’espérais. De par la vitesse d’évolution de ces modèles, il y a fort à parier que les limites que j’ai rencontrés soient rapidement comblés en utilisant des modèles de plus en plus sophistiqués…
Par contre ce qui m’a particulièrement attiré dans cette technologie, est la capacité à fournir rapidement une solution pour mémoriser des informations, les restituer lors d’une recherche et les fournir au modèle LLM pour lui nous formule une réponse à nos question. Cette approche est particulièrement efficace puisque sans connaissance en data science ou en sémantique, nous pouvons réaliser un assistant connecté avec la puissance de GPT pour rendre les interactions avec l’utilisateur encore plus époustouflantes !
Si vous souhaitez aller plus loin avec le Semantic Kernel, je vous invite à suivre la documentation de Microsoft Azure : https://learn.microsoft.com/semantic-kernel/overview ou encore de parcourir le repository GitHub : https://github.com/microsoft/semantic-kernel
Enfin, il existe d’autres moteurs de ce type fonctionnant avec Open AI et les modèles LLM (comme https://docs.langchain.com/docs/), mais à ma connaissance, c’est le seul fournissant une parité OpenAI et Azure Open AI (disponible de manière complètement privée).
Credits
Loins d’avoir un cerveau assez fécond pour inventer cet univers et savoir le décrire, je me suis pris au jeux de GPT pour créer cette histoire. Un autre exemple de ce que nous pouvons produire avec ces modèles et le SK : Le code de l’outils que j’ai utilisé pour générer mon jeux de test est disponible sur mon repository GitHub : https://github.com/kbeaugrand/SemanticKernelDemo/tree/main/ScenarioAuthor
Toute correspondance avec une entreprise existante ou ayant existé est tout simplement fortuite.
En revanche, le tutoriel est bien de moi 😉
