Log Analytics workspace collecte les métriques et logs applicatifs et vous permet de réaliser des requêtes pour pouvoir les exploiter facilement.
Que votre application soit hébergée sur Azure, on Premise ou sur d’autre cloud provider, du PaaS ou du IaaS, Azure Monitor vous offre toutes les solutions pour collecter les métriques et logs et les envoyer dans votre Log Analytics Workspace.
Nous allons voir ensemble comment utiliser une nouvelle fonctionnalité de cette solution vous permettant d’ajouter un point d’entrée HTTPs pour collecter des données personnalisées que vous pourrez exploiter dans votre Workspace.
Data collection endpoint
Le Data collection endpoint est comme son nom l’indique l’interface d’ingestion des données que vous pouvez ajouter à Azure Monitor.
Je le précise ici, en réalité c’est une extension que nous ajoutons à Azure Monitor. Le endpoint peut donc être un endpoint unique pour l’ensemble de vos workspaces d’une même région. Nous verrons ensuite comment sélectionner le workspace de destination par le Data collection rule.
Plus d’infos sur : Data collection endpoints in Azure Monitor
Data collection rule
Le data collection rule va agir dans la solution en tant que ETL (Extract Transform Load) dans votre pipeline d’ingestion de données vers le Log Analytics workspace.
Lors de l’envoi de vos données dans le endpoint vous devrez alors fournir au endpoint l’identifiant du DCR que vous aurez créé.
Plus d’infos sur : Data collection rules in Azure Monitor
Mise en oeuvre
Maintenant que nous avons les éléments de compréhension, voyons comment cela se met en place dans Azure.
Pour cette mise en place, je vous propose ainsi d’effectuer les déploiements des ressources nécessaires par template ARM. En effet, ces fonctionnalités étant disponibles en Preview, l’interface du portail Azure ne permet pas encore toutes les actions que nous allons faire depuis l’interface graphique…
Création d’une table personnalisée
La première étape pour nous sera de créer une table de données personnalisée dans Log Analytics workspace. Le plus simple pour faire cela est d’utiliser un script PowerShell comme celui-ci pour créer une nouvelle table.
$tableName = "AppLogs_CL";
$workspaceResourceId = '<resourceId>'
$table = @{
"properties"= @{
"schema"= @{
"name"= $tableName
"columns"= @(
@{
"name"= "TimeGenerated"
"type"= "datetime"
},
@{
"name"= "Message"
"type"= "string"
},
@{
"name"= "Metadata"
"type"= "dynamic"
}
)
}
}
}
$tableParams = (ConvertTo-Json -InputObject $table -Compress -Depth 4).replace('"', '\"')
az rest `
--method PUT `
--uri "$($workspaceResourceId)/tables/$($tableName)?api-version=2021-12-01-preview" `
--body $tableParams
Après avoir modifié l’ ID de la ressource (celui du Log Analytics workspace) et lancé le script PowerShell, nous pouvons retrouver la nouvelle table dans le portail Azure.
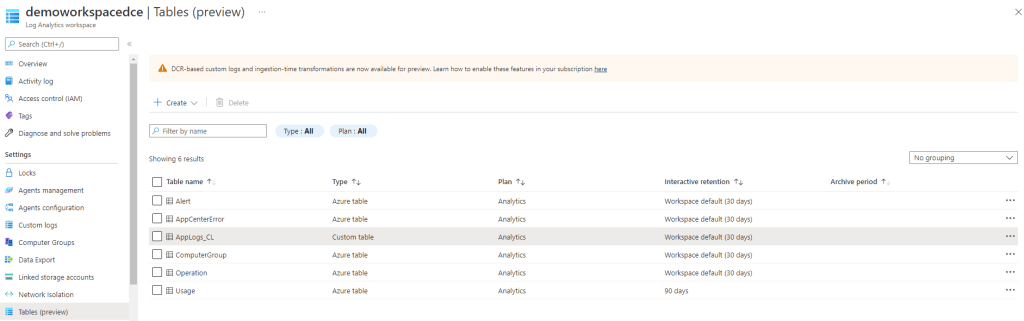
A partir de là, nous pouvons maintenant configurer notre endpoint et notre règle de collection de données dans Azure Monitor.
Création du Data collection endpoint
Le data collection endpoint est comme je le disais un point d’entrée unique de Azure Monitor. Nul besoin donc d’en créer autant que de Log Analytics workspace dans votre région. Cependant, cette ressource n’est pas une ressource globale. Si vous envisagez de l’utiliser pour la collecte de données depuis des machines virtuelles par exemple, veillez à ce que le DCE soit présent dans la même région que la machine virtuelle.
Pour le déployer, rien de plus simple. Je vous colle ici l’exemple de template ARM du Data Collection endpoint tiré depuis la documentation officielle de Docs Azure :
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"dataCollectionEndpointName": {
"type": "String",
"metadata": {
"description": "Specifies the name of the Data Collection Endpoint to create."
}
},
"location": {
"defaultValue": "westeurope",
"allowedValues": [
"westus2",
"eastus2",
"eastus2euap",
"westeurope"
],
"type": "String",
"metadata": {
"description": "Specifies the location in which to create the Data Collection Endpoint."
}
}
},
"resources": [
{
"type": "Microsoft.Insights/dataCollectionEndpoints",
"apiVersion": "2021-04-01",
"name": "[parameters('dataCollectionEndpointName')]",
"location": "[parameters('location')]",
"properties": {
"networkAcls": {
"publicNetworkAccess": "Enabled"
}
}
}
],
"outputs": {
"dataCollectionEndpointId": {
"type": "String",
"value": "[resourceId('Microsoft.Insights/dataCollectionEndpoints', parameters('dataCollectionEndpointName'))]"
}
}
}
Pour ma part, je déploie cela directement depuis le portail en sélectionnant un déploiement d’un Template personnalisé dont je colle le code présent ci-dessus.
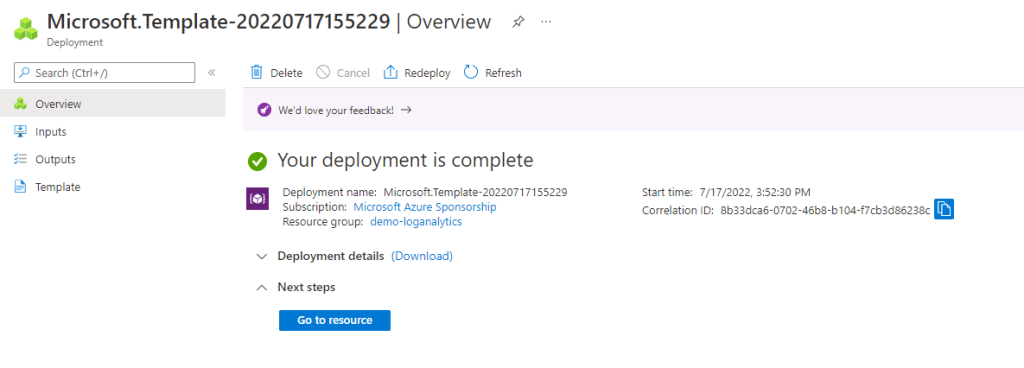
Mon endpoint est maintenant prêt. Je vais pouvoir récupérer les informations nécessaires pour appeler le endpoint :

Création du Data Collector rule
Dernière étape : la création des règles d’ingestion de nos données personnalisées. Je vais réaliser cela par template ARM également, en m’appuyant sur la documentation de Docs Azure :
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"dataCollectionRuleName": {
"type": "String",
"metadata": {
"description": "Specifies the name of the Data Collection Rule to create."
}
},
"location": {
"defaultValue": "westeurope",
"allowedValues": [
"westeurope"
],
"type": "String",
"metadata": {
"description": "Specifies the location in which to create the Data Collection Rule."
}
},
"workspaceResourceId": {
"type": "String",
"metadata": {
"description": "Specifies the Azure resource ID of the Log Analytics workspace to use."
}
},
"endpointResourceId": {
"type": "String",
"metadata": {
"description": "Specifies the Azure resource ID of the Data Collection Endpoint to use."
}
}
},
"resources": [
{
"type": "Microsoft.Insights/dataCollectionRules",
"apiVersion": "2021-09-01-preview",
"name": "[parameters('dataCollectionRuleName')]",
"location": "[parameters('location')]",
"properties": {
"dataCollectionEndpointId": "[parameters('endpointResourceId')]",
"streamDeclarations": {
"Custom-AppLogs": {
"columns": [
{
"name": "Time",
"type": "datetime"
},
{
"name": "Message",
"type": "string"
},
{
"name": "Metadata",
"type": "dynamic"
}
]
}
},
"destinations": {
"logAnalytics": [
{
"workspaceResourceId": "[parameters('workspaceResourceId')]",
"name": "logAnalyticsWorkspace"
}
]
},
"dataFlows": [
{
"streams": [
"Custom-AppLogs"
],
"destinations": [
"logAnalyticsWorkspace"
],
"transformKql": "source | extend TimeGenerated = Time | project TimeGenerated, Message, Metadata",
"outputStream": "Custom-AppLogs_CL"
}
]
}
}
],
"outputs": {
"dataCollectionRuleId": {
"type": "String",
"value": "[resourceId('Microsoft.Insights/dataCollectionRules', parameters('dataCollectionRuleName'))]"
}
}
}
Comme vous pouvez le constater, le Data Collection rule permet de configurer 3 propriétés :
- streamDeclarations : ce sont les endpoints d’entrée de votre Collection rule. Vous pouvez ainsi définir ici plusieurs types d’entrées et définir le format de la payload d’entrée de ces messages
- destinations : Ce sont la liste des destinations possibles
- dataFlows : Ce sont les règles de flux de données que l’on paramère.
Data flows
Petit aparté sur le data flow. Nous pouvons voir ici que le data flow prend plusieurs paramètres :
- streams : Le nom des flux d’entrées sur lequel le flux s’applique
- destinations : Les noms des destinations (que nous avons parémétrés sur le DCR) vers lequel le flux doit envoyer les données
- outputStream : Il s’agit ici du nom de la table personnalisée de Azure Log Analytics workspace que nous avons créée plus tôt. Notez ici que la table porte le nom avec le prefixe « Custom- » indiquant justement au DCR que la destination correspond à une table personnalisée.
- transformKql : Il s’agit ici de la requête permettant de transformer les données en entrée avant de les enregistrer dans la table personnalisée. Ici nous avons la possibilté d’utiliser le language Kusto
Pour plus d’infos sur le langage Kusto et les transformations possibles rendez-vous ici : Kusto Query Language (KQL)
Une fois votre Data Collection rule créé, vous devrez récupérer son identifiant unique. Ceci se récupère sur la vue Json de notre DCR :
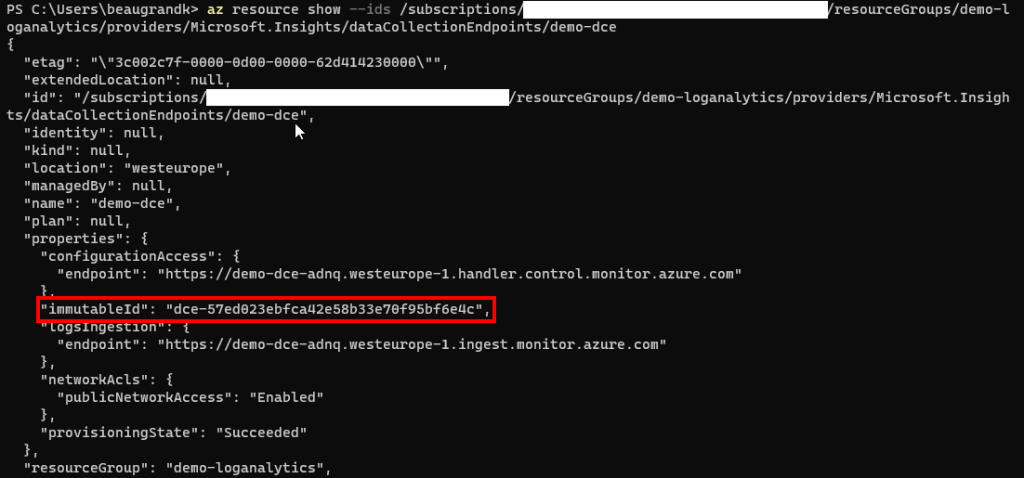
Test du endpoint
Pour pouvoir le tester, vous devrez à minima avoir le rôle Monitoring Metrics Publisher sur le DCR. Dans cette démonstration je vais utiliser mon compte utilisateur à l’aide de la CLI Azure Rest :
$currentTime = Get-Date ([datetime]::UtcNow) -Format O
$data = @(
@{
"Time" = $currentTime
"Message" = "Data1"
},
@{
"Time" = $currentTime
"Message" = "Data2"
"Metadata" = @{
"Property1" = "Value1"
"Property2" = "Value2"
}
}
)
$dceUrl = "https://demo-dce-adnq.westeurope-1.ingest.monitor.azure.com"
$dcrId = "dcr-63c91db391454604979d129220876a0a"
$staticData = (ConvertTo-Json -InputObject $data -Compress -Depth 4).replace('"', '\"')
az rest `
--resource "https://monitor.azure.com/"`
--method POST `
--uri "$($dceUrl)/dataCollectionRules/$($dcrId)/streams/Custom-AppLogs?api-version=2021-11-01-preview" `
--body $staticData
Dans un cas concret, nous aurons à créer une application d’entreprise dans Azure Active Directory qui possèdera ce rôle et qui s’authentifiera sur Azure AD et fournira son ticket d’authentification au endpoint de collection.
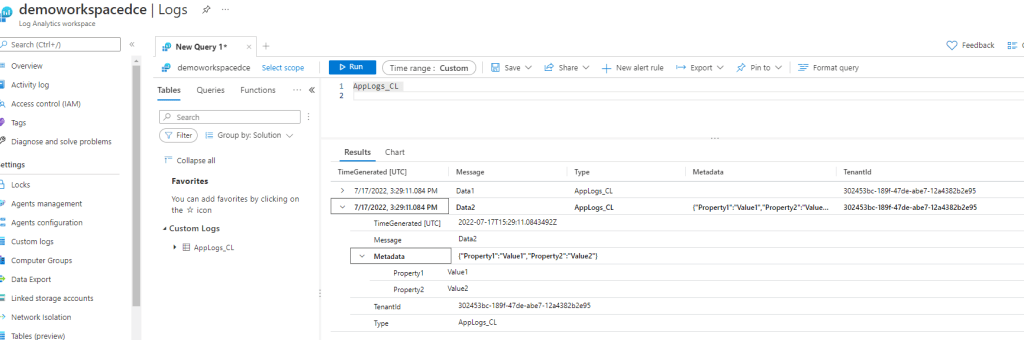
Conclusions
La mise en oeuvre de la fonctionnalité d’ingestion des données personnalisées dans Azure Log Analytics workspace est assez simple. Ce qui est intéressant ensuite c’est que nous n’avons pas grand chose à se soucier. La plateforme Azure gère ensuite la disponibilité du endpoint d’ingestion et du fonctionnement des règles d’ingestion. Les coûts associés sont portées par Azure Monitor et Log Analytics workspace pour l’ingestion et la transformation.
De plus cela nous permet encore une fois de bénéficier de la plateforme Azure Monitor (et Azure Log Analytics workspace) pour ingérer les données applicatives et les analyser directement dans l’outil en les corrèlant avec les autres données que la plateforme Azure collecte déjà pour nous.
Je regrette cependant quelques conventions de nommages dans les ressources (nom de la table avec le suffixe _CL, nom de l’output avec le préfixe Custom-). Je regrette également le manque d’outils de diagnostic sur l’exécution du pipeline. Lors de la création de pipelines de données complexes, il faudra y aller à tâton pour réaliser la requête et pouvoir la debugger.
Rappellons que cette fonctionnalité est encore en preview et qu’il y a fort à parier que les manques seront comblés rapidement.
